



A fecha 28 de julio de 2015 los administradores de sitios en Search Console, el antiguo Webmaster Tools, hemos recibido múltiples avisos del tipo:
Los sistemas de Google han detectado un problema con tu página principal que afecta a la forma cómo nuestros algoritmos renderizan e indexan tu contenido. En concreto, el robot de Google no puede acceder a tus archivos JavaScript o CSS debido a restricciones establecidas en el archivo robots.txt. Estos archivos permiten a Google interpretar que tu sitio web funciona correctamente, de modo que bloquear el acceso a estos elementos puede dar lugar a clasificaciones inadecuadas.
Te contamos qué significa esto, el por qué del aviso, y cómo solucionarlo, ya que si se genera un aviso de algo que no gusta a Google es mejor revisarlo.

Para empezar recomendaría estas lecturas:
https://googlewebmastercentral.blogspot.com.es/2014/05/rendering-pages-with-fetch-as-google.html
https://support.google.com/webmasters/answer/6066468?hl=es
Al final del artículo podrás ver un vídeo de Matt Cuts hablando del tema en 2012.
Contenidos
La explicación
Dentro de Search console, tenemos una zona llamada «Explorar como Google» en la que podemos enviar una URL para que sea rastreada por Google, y así comprobar lo que Google ha obtenido de ella.
Esto sirve para analizar si algún tipo de bloqueo a robots.txt, por ejemplo, ha podido impedir que Googlebot acceda a parte de la información de nuestra web, evitando la indexación de contenido importante.
Por ejemplo
El aviso
Si has recibido un aviso de este tipo significa que efectivamente tienes un problema en este sentido, por algún motivo Google no puede acceder a parte de los recursos y peticiones necesarios para mostrar correctamente tu web y su contenido.
Realmente estos avisos van relacionados con la parte de Render, del procesamiento de la página, pues los CSS y Javascript sirven para convertir la información base en algo más visual y atractivo, y finalmente Google quiere saber como es tu web tanto para su robot, como para el usuario final.
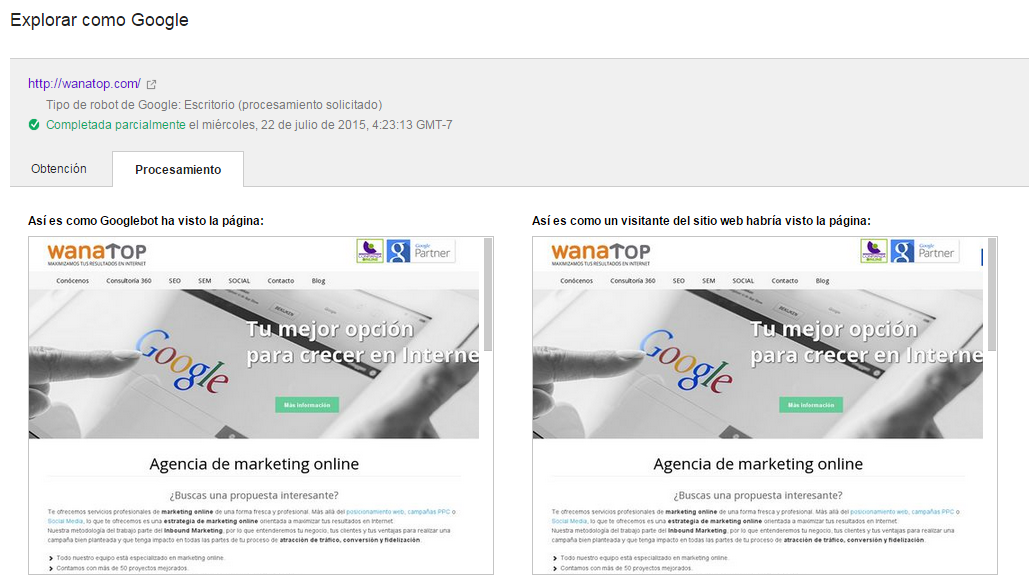
Si todo es correcto al «Explorar como Google» veremos lo siguiente:
Esta es la parte de obtención de datos, de código leído por Googlebot:
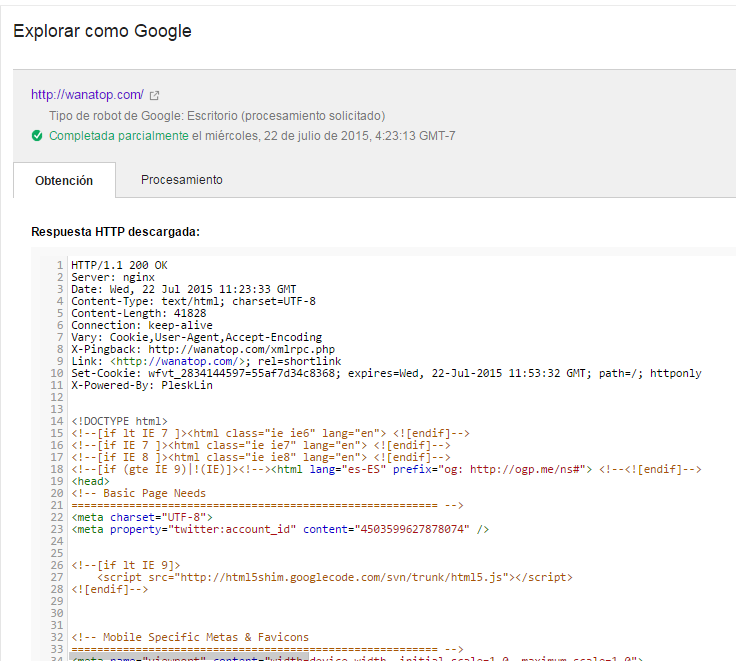
Y esta es la parte en la que Googlebot nos indica si lo que él entiende es lo mismo que ve el usuario, si esto no es así, se genera el problema, pues para Google dentro de su búsqueda por entender a los humanos, es muy importante que sepa como se ve definitivamente la versión una web:
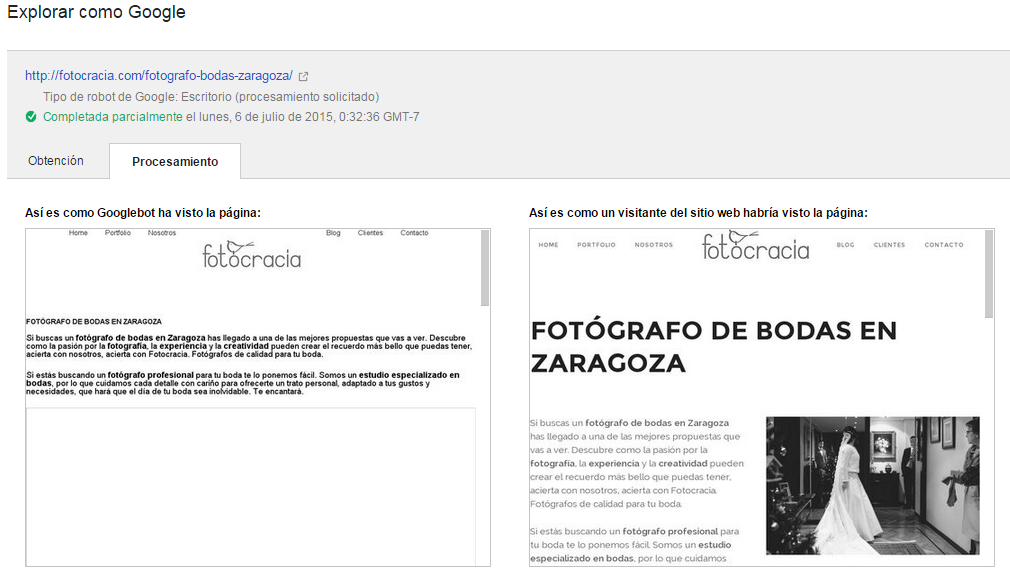
En caso de obtener una versión diferente, tendríamos una aviso como el que ha llegado. En este ejemplo podemos ver que efectivamente ambas versiones del procesamiento difieren, ya que en este caso tenemos parte de los archivos necesarios para el trabajo visual de la web bloqueados en robots.txt:
La solución
La solución es sencilla, Google nos está pidiendo acceso a todos los archivos necesarios para entender correctamente nuestra web tal como lo haría un usuario, en este caso es muy claro especificando la necesidad de los CSS y JS.
En muchas webs bloqueamos mediante robots.txt el acceso a zonas de archivos de plantilla o zonas de administración para que no sean indexadas en el buscador y no tener exposición pública mediante Google a archivos delicados.
En caso de Wordpress por ejemplo no dar acceso a la zona de plugins o temas es la que puede provocar este aviso.
En el caso de Prestashop el acceso a la carpeta modules viene bloqueada en robots.txt por defecto, causa del problema.
Lo que tienes que hacer es detectar todas las peticiones CSS y JS que realiza la página durante su carga, usando herramientas como GTMetrix o Pingdon Tools, y dando acceso a Googlebot.
Para editar Robots.txt necesitarás acceder a él mediante FTP, o en caso de algunos CMS como Wordpress tienes plugins para editar directamente el archivo desde la administración.
Podemos comprobar de manera sencilla que todo está correcto enviando la URL a «Explorar como Google» y comprobando que las versiones de usuario y Google Bot coinciden.
Tenemos peticiones de sobras para realizar los crawls necesarios para mostrar todo.
Según tu web y la manera en la que hayas construido tu web tendrás una problemática u otra, incluso hay técnicas de link sculpting que pueden chocar con este requerimiento de Google, en cualquier caso tendrás que realizar lo necesario para que el robot tenga acceso a todo lo necesario para ver la web como el usuario.
Esperamos que este pequeño artículo, hecho con cierta prisa dada la voz de alarma, te haya sido de utilidad.
Recuerda que estamos al tanto de los comentarios para poder ayudarte en lo que necesites, igualmente estaremos encantados de que compartas tus opiniones y consejos.
Publicaciones relacionadas:




 Alberto López, Fundador y CEO.
Alberto López, Fundador y CEO.